
Most cybersecurity tools were built for systems that behave the same way every time you run them. AI systems don't. That difference creates gaps that traditional security doesn't fully cover.
Traditional security assumes predictability — the same input always produces the same output. AI systems are unpredictable by design. That one difference reshapes how you need to think about attack surfaces, testing, detection, and defense. Below is a walkthrough of what changes, where the gaps are, and what you can do about them today.
The Assumption Underneath
Traditional cybersecurity rests on an assumption: determinism.
Think of a web server. You send it a request, it sends back a response. Send the same request tomorrow, you get the same response. A database, an authentication system, an API — these all work the same way. Predictable in, predictable out.
This predictability is baked into how we do security. Vulnerability scanners look for known flaws. Penetration testers probe endpoints and document what they find. Incident response playbooks tell you what to do when something breaks. All of it works because the system you're testing behaves the same way each time.
Even the concept of a "known vulnerability" depends on this. A vulnerability is a specific, reproducible flaw in a specific piece of software. You find it once, you can find it again. You patch it, it stays patched.
AI systems don't work this way.
A large language model given the same prompt twice can return two different answers. A system that retrieves information from a knowledge base gets different results as that knowledge base changes. An autonomous agent decides which tools to call, and in what order, based on context that shifts between runs.
The behavior comes from the interaction between the model, the data, the context, and the environment. None of those is fully predictable. A model might handle a prompt well on Tuesday and fail on Wednesday because its context window has different information in it.
This doesn't make AI systems broken. It makes them a different kind of system. And security frameworks built for predictable software have blind spots when applied to systems that aren't.
What Changes
This doesn't mean you throw out your existing security practice. Identity still matters. Access controls still matter. Encryption still matters. Network segmentation still matters. But several core concepts need to be extended.
The attack surface is no longer static. In a traditional system, you can understand the attack surface by looking at the architecture. Here are the ports. Here are the API endpoints. Here are the routes. You can scan them, test them, document them. The list doesn't change unless you deploy new code.
An AI system's attack surface depends on what the model decides to do at runtime. An agent that can call external tools, browse the web, or write and execute code has an attack surface that shifts as it makes decisions. You can scan the known architecture in advance. But the full attack surface doesn't exist until the system actually runs.
Input validation means something different. In traditional security, input validation is direct. Check the data type. Check the length. Sanitize for known injection patterns. The rules are specific and testable.
With AI, the input is often natural language. A user types a question or gives an instruction. The validation question isn't "is this the right format." It's "will this input cause the model to produce an output that violates our security policy." That's closer to defining correct behavior than validating data. And defining correct behavior for a system that responds differently each time is harder.
Testing provides less assurance. In deterministic systems, if you test a code path and it behaves securely, you have reasonable confidence it will behave securely in production. You tested the actual path the software will take.
With AI, passing a test means the system behaved securely under those specific conditions with that specific input at that point in time. A slightly different prompt, a different context window, a different model version — and the system might behave differently. Testing still matters. But a passing test provides less assurance than it does for deterministic software.
"Patching" has a wider blast radius. In traditional software, a vulnerability gets a patch. A specific fix for a specific bug. Applied once, verified, done. The rest of the software behaves the same as before.
When an AI system has a problem, the fix is less targeted. It might involve retraining the model. Fine-tuning it. Adjusting the system prompt. Adding guardrails. Modifying the retrieval pipeline. Each of these changes affects the model's behavior across all inputs, not just the one that caused the problem. Fixing one issue can introduce another.
Detection Was Built on Predictability
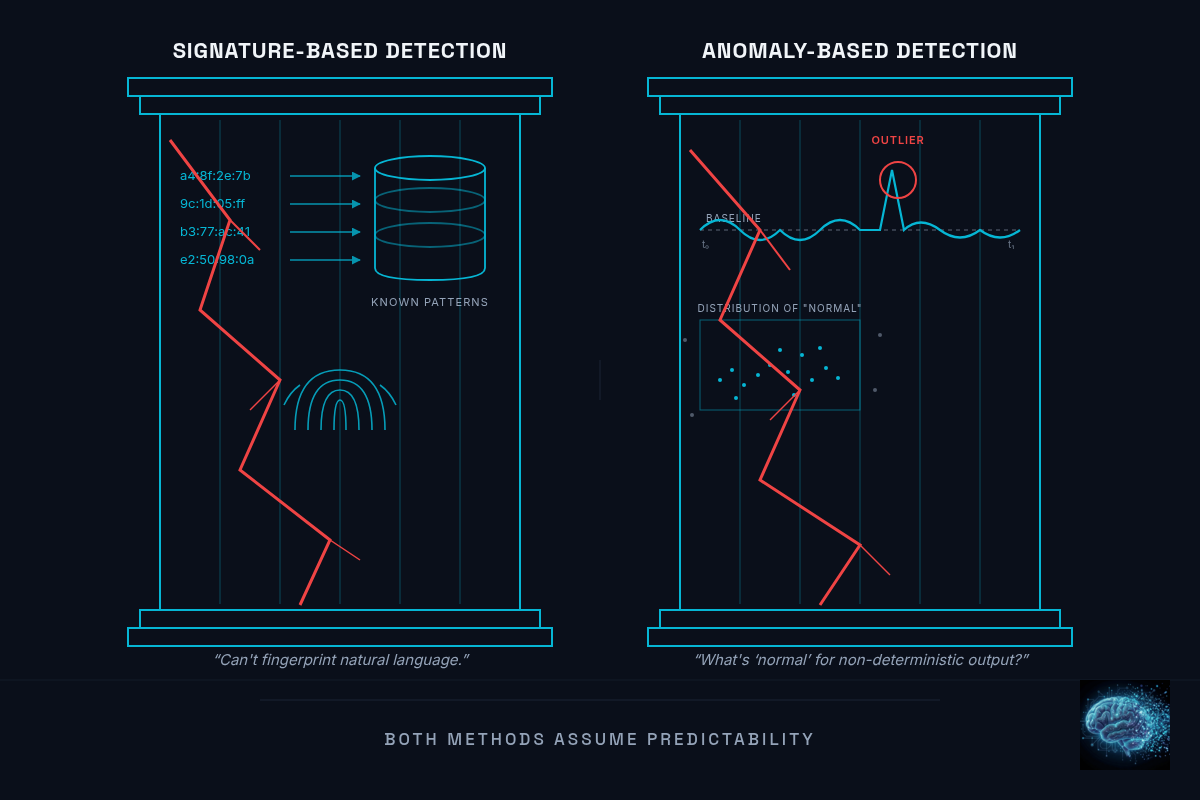
Traditional cybersecurity relies on two methods to detect threats: signature-based detection and anomaly-based detection. Both are predictive. Both assume you can identify what a problem looks like before it happens.
Signature-based detection matches known patterns. A database of known malware signatures, known exploit patterns, known malicious IP addresses. Your system sees traffic that matches a signature, it flags it. This is the oldest and most reliable detection method in cybersecurity. It's effective because it's specific — a signature matches one known threat, and you know what it caught.
The limitation: it only catches what's been seen before. A new exploit technique, a zero-day vulnerability, a modified version of known malware — these won't match any signature in the database. The detection is only as good as the library of known threats. The arrival of AI attackers has rendered signatures all but obsolete.
Anomaly-based detection was built to solve that problem. Instead of matching known bad patterns, it establishes a baseline of normal behavior and flags deviations. If a user normally logs in from New York during business hours and suddenly there's a login from Eastern Europe at 3 AM, the detector flags it.
This works well for deterministic systems because "normal behavior" is relatively stable. A web server serves pages. A database processes queries. The patterns are consistent enough to build a reliable baseline.
Both methods are predictive. You define what "bad" looks like (signatures) or what "normal" looks like (baselines) before the system encounters the threat. You're building a model of the world in advance and checking incoming events against it.
Here's where this breaks down for AI.
Signature-based detection doesn't map well to AI threats. What's the signature for a prompt injection attack? The input is natural language. It doesn't look like malware. It doesn't have a file header or a payload structure to match against. The same sentence might be harmless in one context and exploitative in another. The attack lives in the meaning of the words and the effect they have, not their structure.
Anomaly-based detection runs into a different problem. AI systems are non-deterministic, so "normal behavior" is harder to define. A model that generates different responses to the same prompt isn't malfunctioning — it's working as designed. An agent that calls different tools in a different order on different runs isn't anomalous — it's adapting to context.
What's "normal" for a system designed to produce different outputs each time?
Where the Gaps Are
Understanding that AI security is different is a start. The more useful question: what specific gaps exist in current practice, and what can you do about them?
Gap 1: No Standardized Way to Define "Secure Behavior" for AI
In traditional security, you can write a clear specification. The system must reject inputs over 256 characters. It must authenticate all requests. It must log all access events. Binary rules. Testable. Auditable.
For AI, the specification is usually something like "the model should not produce harmful output." What counts as harmful? In what context? At what probability threshold? Different organizations and regulators answer these differently. There isn't a widely adopted standard for turning "don't produce harmful output" into something you can test.
NIST's AI Risk Management Framework provides governance structure but stops short of technical specification. OWASP's Top 10 for LLM Applications identifies vulnerability categories but doesn't define "secure" at the implementation level. The honest answer is we don't fully have this figured out yet.
What practitioners can do now: Threat modeling is not optional. Define threat models specific to your AI deployment: (1) what outputs are unacceptable, with concrete examples, not just categories; (2) what inputs are out of scope for your use case; (3) what the model should do when it encounters an input it can't safely handle. A documented threat model gives your team something to test against, even if it isn't perfect.
Gap 2: Guardrails Detect Better Than They Enforce
AI guardrails — system prompts, output filters, content moderation layers — are a primary defense for most AI deployments. They're also non-deterministic. A system prompt tells the model to refuse harmful requests, but the model's compliance depends on the input, its training, the context window, and how much adversarial pressure is applied.
Where guardrails have real value is in detection. A guardrail that flags a suspicious input for human review, or a filter that tags a response for post-processing, doesn't need to be perfect. It needs to reduce the volume of threats that reach a human reviewer.
The problem is enforcement. When a guardrail is the gatekeeper — deciding what inputs reach your production model and what gets blocked — the calculus changes. Attackers don't generally get one attempt, they get as many as they want. Each probe that gets blocked reveals information about where the boundary is. A guardrail that catches 95% of injection attempts on the first try might catch 80% on the third try and 60% on the tenth, as the attacker refines their approach based on what passes through.
Guardrails can also fail for being non-deterministic themselves. If a guardrail depends upon an LLM to identify whether a particular prompt constitutes prompt injection, then it has the same dependency on language interpretation as the model it protects.
Most research evaluating guardrail effectiveness tests against static benchmarks — known attack types, single-turn interactions. The results look strong. But small changes in the prompt change the calculation. Against iterative probing: an adversary who sends dozens of variations, observes which ones pass, and adapts in real time. That's how real attacks work, and it's where enforcement guardrails degrade fastest.
This doesn't mean guardrails are useless but they cannot be the only, or even the primary, defense. Use them to flag suspicious inputs and outputs. Route flagged inputs to human review. Architectural constraints — capability scoping, sandboxing, allowlists — provide more reliable enforcement because they don't degrade under iterative probing.
What practitioners can do now: Separate your guardrail strategy into detection and enforcement. Use guardrails as a detection layer — flag, don't block. Route flagged inputs to human review or a more capable analysis model. For enforcement, rely on architectural controls: capability scoping, sandboxed execution, tool access allowlists, separate models for different risk levels, and data access control. Design so that a guardrail bypass doesn't grant unrestricted access. The goal: detection catches the noise, architecture catches the signal.
Gap 3: Supply Chain Risk Has a New Dimension
Traditional software supply chain security focuses on dependencies. Libraries, packages, containers. You audit them, pin versions, scan for known vulnerabilities. The tools are mature.
AI introduces a supply chain risk that doesn't fit this model. The model itself is a dependency. Trained on data you may not fully control. Built by a process you didn't supervise. Updated on a schedule you don't set. A model update can change your system's behavior across every input at once, with no change to your code. Model versioning exists, but it doesn't guarantee behavioral consistency the way software versioning does.
Training data is another vector. Data poisoning — introducing manipulated data into the training set — can create backdoors that are difficult to detect. The underlying vulnerability can't be fully patched without retraining. Output filtering and runtime monitors can reduce the impact, but the poisoned model still has the vulnerability baked in.
Then there's a risk most organizations aren't accounting for: AI is now embedded in products they buy. Your CRM vendor added an AI copilot. Your helpdesk platform uses language models to classify tickets. Your security tools are starting to incorporate AI for threat detection. In each case, a model you didn't select, didn't train, and can't inspect is processing your data and making decisions that affect your operations.
This is a supply chain problem your existing tools weren't built for. Software dependency scanners look at code. They don't look at model behavior. Vendor security questionnaires ask about encryption, access controls, and incident response. They don't ask what model the vendor is using, how it's trained, what data it was trained on, or whether it changes without notice. You can pin a library version. You can't pin a model behavior.
The blast radius is wider than most security teams realize. An AI component in your CRM could leak customer data through a model vulnerability. An AI-powered security tool could produce false negatives that create a real gap in your defenses. A vendor's model update could change how your data is processed without any change to your contract or your configuration.
What practitioners can do now: Treat model updates as high-risk deployments, whether the model is yours or your vendor's. Run behavioral regression tests before and after every version change — not just accuracy benchmarks, but security-relevant behavior. Does the model refuse the same prompts? Handle the same edge cases? For vendor-embedded AI, demand transparency: what model are you using, what data does it process, how are updates communicated, what's the rollback process if a model change causes a security issue. Include AI components in your vendor risk assessments. For high-stakes deployments, consider evaluation frameworks like HELM that provide structured assessment across safety dimensions.
Gap 4: Observability Lags Behind
In traditional systems, observability is well established. Logs, metrics, traces. You can reconstruct what happened, when, and why.
AI systems generate signals that most observability stacks weren't designed to capture. The model's reasoning chain. The context it retrieved. Its confidence distribution. The intermediate decisions in an agent's execution path. These are the signals that tell you what the system was actually doing.
Most AI deployments today have limited visibility into these signals. The model receives an input and produces an output. What happened in between is largely opaque. Investigating an incident without knowing what the system was doing means relying on incomplete information. Detecting anomalous behavior without a baseline for normal behavior means catching only the most obvious deviations.
Then there's the deeper problem: the model itself is a black box. In traditional software, when something goes wrong, you can trace the execution path. You can read the code that produced the output. You can set breakpoints, add logging, and follow the logic step by step. If a function returns the wrong value, you can find exactly where and why.
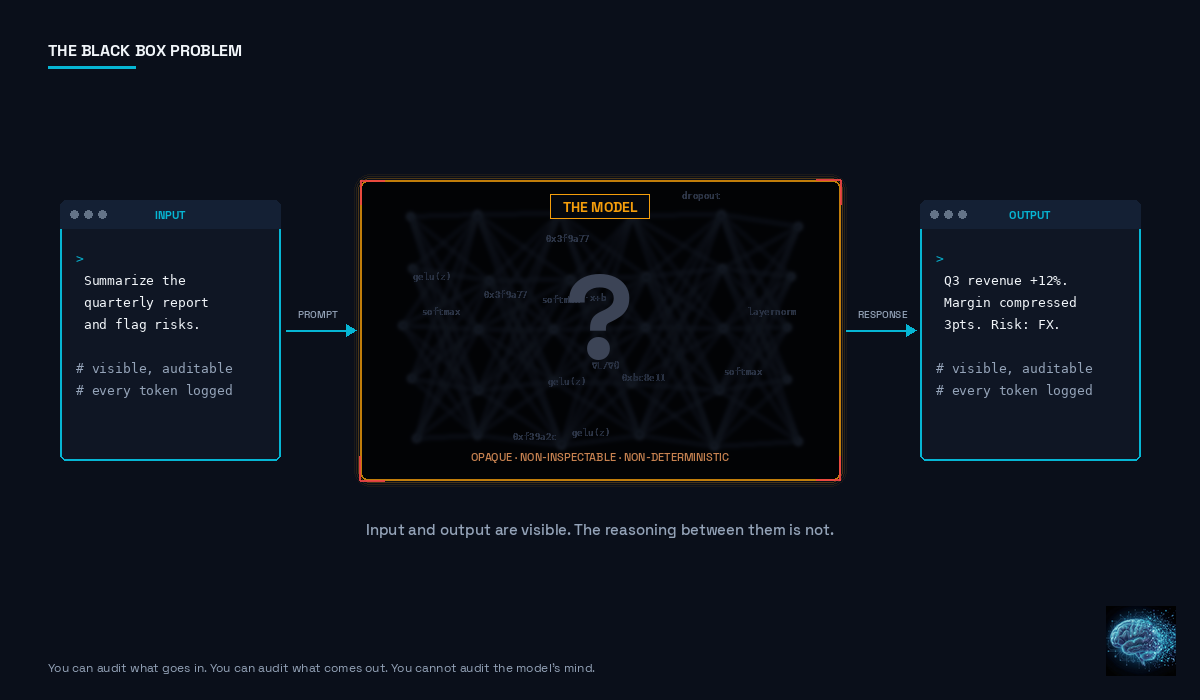
A language model doesn't offer that. The relationship between an input and an output is determined by billions of parameters distributed across layers of a neural network. There is no line of code to inspect. No execution path to trace. When a model produces a harmful output, you can see the input and the output, but the reasoning that connected them is not directly observable. You can use interpretability techniques — attention visualization, probing classifiers, feature attribution — but these are approximations. They suggest what the model might be doing. They don't show you what it is doing.
This matters for security in a specific way. If you can't see how the model arrived at an output, you can't reliably distinguish between a model that handled a prompt safely and a model that handled it safely by coincidence. A model might refuse a prompt because it understood the malicious intent. Or it might refuse because the phrasing happened to trigger a safety pattern in its training. Those are different failure modes with different implications, and without visibility into the model's reasoning, you can't tell them apart.
What practitioners can do now: Instrument what you can. Log input and output pairs. Log retrieval sources. Log tool calls and agent decision paths. Log model confidence scores where available. Store with enough retention to support incident investigation. But be honest about the ceiling: observability around the model is not the same as observability into the model. You can build a strong picture of what went in and what came out. The reasoning in between remains an informed guess. Design your security posture around that limitation, not in denial of it.
Toward a Practical Framework
These gaps don't require reinventing security practice. They require building upon existing security investments, processes, and architecture.
1. Threat model the AI-specific surface. Your existing threat model covers infrastructure, access controls, and data handling. Add a layer for the non-deterministic component. What can the model do at runtime? What tools can it access? What data can it retrieve? What happens if it makes a wrong decision?
2. Give every agent an enforceable identity. In traditional systems, access control is tied to identity. Users, service accounts, API keys — each one has permissions, audit trails, and lifecycle management. AI agents need the same treatment. Every agent should have its own identity with scoped permissions that can be enforced, audited, and revoked. Not a shared service account. Not inherited permissions from the application that launched it. A distinct identity with its own access boundaries, its own audit log, and its own lifecycle. When an agent is decommissioned, its access goes away. When an agent is compromised, you can isolate it without affecting other agents or human users. This is existing IAM infrastructure applied to a new class of actor.
3. Architect for containment. Prevention will fail sometimes. Design the system so that when it does, the damage is limited. Capability scoping. Allowlists. Sandboxed execution environments. Human-in-the-loop checkpoints for high-impact operations. These work regardless of whether the system is deterministic.
4. Test behaviorally, not just structurally. Static analysis and code review catch some issues. Behavioral testing — adversarial inputs, red-team exercises, edge-case probes — catches different issues. Relying on one without the other leaves gaps. Build a test suite with adversarial prompts specific to your threat model. Run it against every model update.
5. Observe what the model actually does. Instrument for AI-specific signals. Establish a behavioral baseline during normal operations. Set alerts for deviations. The sooner you detect a behavioral shift — whether from an update, adversarial input, or context change — the faster you can respond.
6. Document your uncertainty. For gaps without a good answer yet — and there will be some — document them. "We don't have a reliable way to detect X yet" is more useful than silent uncertainty. It tells your team where to focus, tells auditors where the risk lives, and tells leadership what the actual risk profile looks like.
What This Means in Practice
Traditional cybersecurity isn't going away. The organizations that handle AI security well won't be the ones that throw out their existing practice. They'll be the ones that recognize where it needs to be extended and build the additional layers.
Some of these gaps don't have clean solutions yet. Non-deterministic systems are harder to secure than deterministic ones. Pretending otherwise doesn't help anyone. What helps is acknowledging the difference, documenting where the gaps are, and building practice that accounts for what AI systems actually are. Not what we wish they were.
Subscribe to the newsletter for bi-weekly analysis → substack.com/@adversarialminds
Steve Brodson is a cybersecurity architect focused on AI safety and security. He experiments with AI systems, consults with organizations navigating AI risk, and teaches practitioners how to think clearly about threats that don't fit traditional security frameworks. Connect on LinkedIn, X, or at brodson.com.