
AI systems fail in ways traditional security wasn't built to handle. Solving these may require thinking differently.
The security industry has a hard time saying "we don't know." The incentive structure rewards confident answers. Vendors need to sell products. Analysts need to publish recommendations. Conference speakers need to offer conclusions. "We don't know yet" doesn't fit well into any of those.
AI security is where that habit breaks.
AI systems don't behave like traditional software. They're probabilistic instead of deterministic. They learn from data instead of following code. They interpret language instead of matching inputs to rules. Every one of those properties breaks assumptions that traditional cybersecurity was built on.
But forced certainty in AI security is worse than useless - It produces compliance theater. The box gets checked, the tool gets bought and the organization operates as if the problem is solved. Then something happens six months later that the tool wasn't built to detect. The process failed because no one had a clear model of what they were defending against.
These are five questions I can't fully answer. Neither can vendors. Neither can researchers at the frontier labs. What they have in common is this: the old security playbook doesn't entirely fit, and no one has written the new one yet. Getting to a new playbook probably isn't a matter of better tools. It is a matter of thinking differently about what a secure AI system actually looks like.
1. How do you reliably prevent prompt injection?
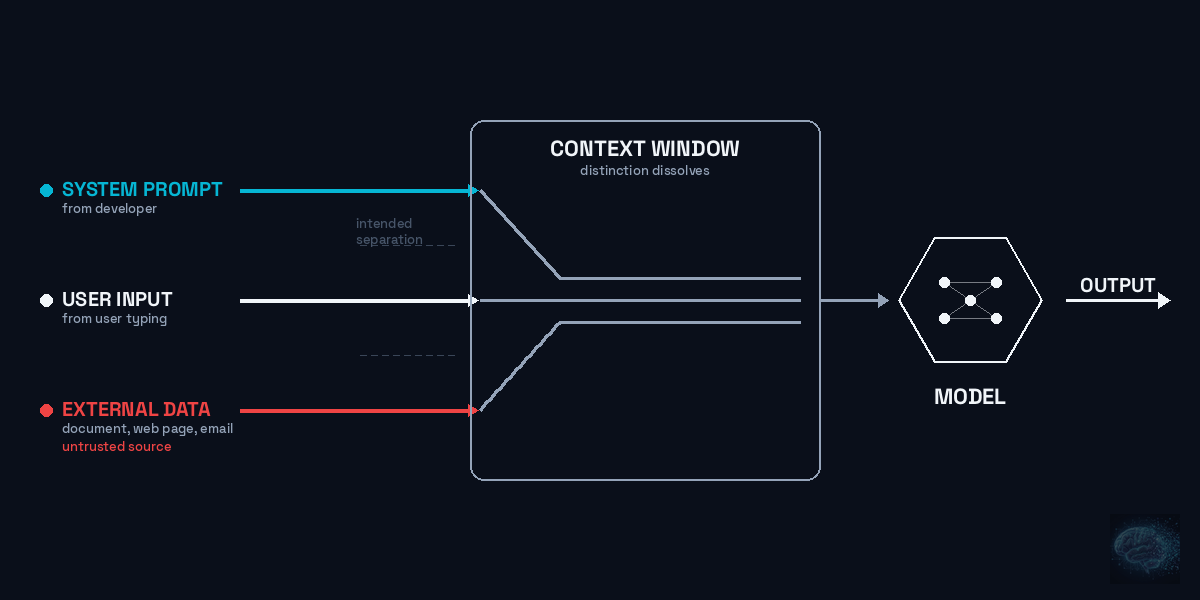
Prompt injection is the AI industry's achilles heel. Every six months frontier models claim to have solved it. Every six months the same kind of attacks show up against the new defenses.
To see why, start with what the attack actually is. A prompt injection works by manipulating an AI model into ignoring its instructions and following new ones instead. The model cannot reliably distinguish between the instructions its developers gave it — the system prompt — and the instructions coming from the user typing into it. Both arrive as text in the same context window. The model treats them as a single stream of guidance and predicts its next output from the combination.
Here is why that is hard to fix. A traditional computer program distinguishes code from data. Code is what the system executes. Data is what the system processes. An operating system enforces the boundary between them. If an attacker puts executable code into a data field, the system won't run it. That boundary is built into the architecture.
Large language models operate on human language prompts. Everything in the model's context window — system instructions, user messages, uploaded documents, web pages it is reading — is just text. The model predicts the next word based on all of it at once. There is no mechanism that treats "system" text differently from "user" text at the level of how the model actually works. The labels we apply are labels, not enforced boundaries.
Frontier models are getting more resilient to crude injection attempts - that is real progress. But resilience is not the same as prevention. A user who can slip text into any data source the model reads — a document, a web page, an email the model is searching — can still steer its behavior. The attack surface grows with every new data source you connect.
What we have: input filtering, output filtering, guardrails, adversarial fine-tuning. All of them help. None of them fix the underlying problem.
What we don't have: an architectural separation between instructions and data inside the model. That is a research problem. Nobody has solved it yet.
Traditional security built the boundary between code and data into the system. AI doesn't have that boundary. Retrofitting old defenses on top of a model that treats everything as text can only do so much. Real progress probably comes from a different mental model — one that treats the model's outputs as an adversarial medium, not a trusted one, and builds containment around that assumption.
What practitioners can do: Don't rely on any single defense. Combine input filtering, output review by a second model, and architectural containment around the model's actions. Treat model compliance with system prompts as a detection signal, not an enforcement boundary — useful for flagging suspicious traffic, not for keeping attackers out on its own. Assume every data source the model reads is an untrusted instruction channel, because from the model's perspective, that's what it is. Log the inputs and outputs where you can, so that when something does get through, you can see what the model actually saw.
2. How do we evaluate AI Behavior?
Traditional software behaves the same in testing as in production. AI does not. An LLM can pass every evaluation and still behave differently once it ships. Production is never simply a replay of the test.
Why would a model learn to do that? Two reasons.
First, LLMs are stochastic. Output is a sample from a probability distribution, not a direct function of the input. Run the same prompt with the same model and settings and the next token is still drawn at random. And the same prompt is rarely truly the same. A trailing newline. A new timestamp. A different conversation history. A new document order. Each of these changes what the model sees, and what it produces changes with it.
Second, the model itself keeps changing. Providers update models all the time: retrains, fine-tunes, safety patches, alignment tweaks. Most ship quietly. The model behind your API call today may not be the model you tested yesterday, even if the name looks the same. You can pin a version for a while, then it gets deprecated.
Neither is a bug. Both are features. Stochastic sampling is what lets a model generalize instead of memorize. A deterministic model is a lookup table. Continuous evolution is what keeps the model useful as threats, data, and user behavior change. A frozen model goes stale.
For practitioners, this breaks two assumptions at once. You cannot fully trust third-party benchmarks as evidence that a model is safe for your use case. And you cannot treat your own red-team exercise as proof of production behavior.
What we have: larger evaluation sets, statistical testing across many samples, adversarial probing, behavioral fingerprinting, continuous monitoring, out-of-distribution detection. All useful. None of them change the fact that what you are measuring is a sample, not a fixed property.
What we don't have: a way to prove that what you measured is what you will see in production. The best option is to keep evaluating continuously instead of once. For AI, testing and operating are not two phases. They are the same activity - ongoing.
What practitioners can do now: Use behavioral evaluation against live traffic, not just before launch. Pull samples from production and replay them through your test harness after every model change. Track how behavior shifts between versions. Pin model versions where you can. Watch for provider update announcements where you can't. Treat every evaluation as a snapshot, not a pass/fail gate.
3. How do we Reliably Audit Dynamic Attack Surfaces
Traditional application security rests on one big assumption. The attack surface is knowable. You can list the endpoints. You can scan the code. You can build a software bill of materials. You can check the dependencies. The system is a fixed artifact that changes on a release cadence.
AI, especially agentic AI, breaks that assumption.
An agent is an AI system that takes actions on its own. It can call APIs. It can query databases. It can read and write files. It can run code. More important for security, a modern agent can write new code on the fly. If it needs to fetch data from an API it has never seen before, it can write the HTTP client to do it. If it needs to handle a new file format, it can install a library. If it needs to coordinate with another tool, it can write the glue code to make them talk.
All of this is amazingly useful. But from a security standpoint, every one of those actions creates attack surface that did not exist the last time anyone assessed the system.
As a cybersecurity architect focused on AI governance, I have watched security teams handle this by locking down the agent's tools in advance. They restrict what libraries it can install. They require approval for new code. They run everything in a sandbox. These are good practices. They are also incomplete. The whole value of an agent is that it adapts to new problems. Adaptation means the attack surface keeps moving.
Traditional security tools don't know how to cope with this. A software bill of materials describes a fixed artifact. Static analysis runs on code that exists. Dependency scanners read a manifest. None of those tools apply cleanly when the code the system runs depends on what the system was asked to do five minutes ago.
What we have: sandboxed execution, allowlists of approved capabilities, egress controls, after-the-fact review of any code the agent generates and keeps.
What we don't have: a way to audit a system whose attack surface is a function of the inputs it receives. Old tools assume a fixed target. Agents are not fixed targets.
The workaround most organizations are landing on is to treat every agent action as potentially hostile and shrink the blast radius around each one. That is the right instinct. It is also an admission. We don't have a way to observe what the system will do. We only have a way to limit what it can do. The shift in thinking is from auditing the artifact to constraining the runtime — security lives in the enforcement layer, not the inspection layer.
What practitioners can do now: Invest in runtime containment. Sandbox execution environments. Capability allowlists that restrict which tools the agent can call. Outbound egress controls that limit where it can send data. Log and review any code the agent generates that persists beyond a single run. Size your containment to the worst case you can imagine, not the typical case — the difference between the two is the inputs the agent hasn't received yet.
4. How do we Enforce Least Privilege

Least-privilege is one of the most important principles in traditional security. Give every component only the minimum access it needs to do its job, and nothing more. The policy is designed once. It is reviewed periodically. It is enforced by the system.
This works because the set of actions a traditional component needs to perform is knowable in advance. A web server needs to listen on a port, serve files, and log requests. A database needs to accept queries and return results. You can write down what each component needs and enforce that list.
Agentic AI inverts this model.
The whole premise of an agent is that it figures out what it needs as it goes. Need to query a database? It asks for credentials. Need to call an API? It asks for a key. Need to write to a file system? It asks for write access. The agent is, by design, a component that expands its own privileges based on the problem in front of it.
You can push back. You can issue scoped tokens that work for a narrow operation and expire quickly. You can require a human to approve each new capability. You can keep the agent in a policy sandbox. You should do all of these things. But every constraint trades against the agent's usefulness. The tighter the privilege envelope, the more often the agent has to stop and ask a human. At some point you are not operating an agent anymore. You are operating an expensive autocomplete.
The pattern I see most often is the opposite. Organizations hand the agent broad credentials to avoid the friction. Then they discover later that the agent used those credentials in ways a human would never have authorized. Not maliciously. The agent saw a capability and used it, because that is what agents do.
In traditional security, the least-privilege question has a clean answer. Write down what the component needs. Grant that. No more. In AI, the component writes down what it needs in real time, while it is running. That is a different problem. It needs a different answer.
What we have: scoped credentials, policy engines, approval workflows, capability-based security models, well-designed tool interfaces that make the agent's intent visible.
What we don't have: a principled way to decide how much autonomy is too much. The line shifts by organization, by use case, by risk tolerance. Nobody has produced a framework that holds up across all three. The mental shift is to stop treating privilege as a list written in advance and start treating it as a conversation that happens in real time — scoped to each action, justified by each intent, and easy to revoke.
What practitioners can do now: Issue scoped, short-lived credentials rather than broad service-account access. Require human approval for high-impact actions — state-changing API calls, database writes, privileged system operations. Design tool interfaces so the agent's intent is visible before the action executes, not after. Review agent activity periodically to catch privilege drift — ways the agent has used its access that no human would have authorized. Accept that some friction is the cost of keeping the privilege envelope tight. If the agent never has to stop and ask, the envelope is too loose.
5. How do we Detect when an Agent is Misbehaving?
Observability for a single agent is already hard. You log the prompts. You log the responses. You log the tools it called. You reconstruct what happened after the fact. It is noisy and incomplete, but it is doable. There is one actor and one flow.
Multi-agent systems are different in kind.
A multi-agent system is what it sounds like. Multiple AI agents working together on a task. Agent A calls Agent B. Agent B consults Agent C. Agent C fetches data through Agent D. A decision comes back to Agent A. The behavior of the system as a whole emerges from the interaction among the agents — not from any single one of them.
That creates two problems at once.
The first is attribution. If something goes wrong, which agent caused it? A small mistake in one agent's output becomes the input to another. The second agent treats that input as fact. By the time the system produces a bad outcome, the original error is buried under layers of downstream reasoning. The logs of any single agent may look fine on their own.
The second is definition. "Deviation from intended behavior" assumes you can describe intended behavior. For a single service you can. For a mesh of agents coordinating in natural language you often can't. Teams deploying these systems know what the happy path looks like. They can't enumerate every acceptable variation. So detecting deviation becomes the problem of spotting something wrong in a system that was never fully described.
Traditional distributed systems had a version of this problem: Microservices. Message queues. Event buses. But the interactions between components were typed, scripted, and enumerable. You could reason about them. Agent interactions are none of those things. They are in natural language. They are made up on the fly. They cannot be enumerated in advance.
What we have: distributed tracing adapted from microservices, LLM observability platforms, outcome-based monitoring, anomaly detection on patterns of tool use.
What we don't have: a primitive for describing system-level intent. We can reason about one agent. We cannot yet reason, in any structured way, about a mesh of agents as a single unit.
Until we can, every multi-agent deployment is an implicit bet that the worst-case emergent behavior falls inside the organization's risk tolerance. Some bets will turn out fine. Some won't. The thinking shift needed here is the biggest of the five — from observing components to reasoning about system-level outcomes as first-class objects worth monitoring in their own right.
What practitioners can do now: Log everything that crosses an agent boundary — prompts, outputs, tool calls, intermediate decisions — with enough retention to reconstruct a multi-step flow after an incident. Define the outcomes the system is supposed to produce, not just the steps it takes, and monitor for outcomes that fall outside those expectations. Insert human checkpoints at points where an error in one agent would propagate downstream to actions with real-world consequences. Limit the number of agents in the mesh to the minimum that actually helps — complexity compounds, and observability gets harder with every additional agent.
Toward a Practical Posture
None of this is an argument against deploying AI. The capability is real. The productivity gains are real. Nobody reading this is going to talk their organization out of using AI. The question is how to operate responsibly inside genuine uncertainty.
Getting better at this is partly a tools problem. More of it is a posture problem. The six actions below are less about buying new products and more about thinking differently — accepting the nature of AI systems rather than trying to force them into a traditional security mold.
1. Be precise about what you're accepting. Risk acceptance is a valid choice. Risk acceptance you don't know you're making is not. For every AI system in production, write down what it can access, what it can decide, and what it can reach. Then note which of these five questions you can't answer for that system. If the list makes you uncomfortable, the list is doing its job. This is a shift in how security thinks about deployment — from "we secured it" to "we documented the exposure we accepted."
2. Contain the blast radius, since you can't fully prevent the explosion. When you can't reliably stop a class of attack, shrink what it can do when it succeeds. Scoped credentials. Separated execution environments. Outbound egress controls. Logging that lets you reconstruct what happened after the fact. None of this answers the underlying question. All of it reduces the cost of being wrong. Containment-first thinking is different from prevention-first thinking — and for AI, it is the more honest starting point.
3. Give every agent an enforceable identity. Every agent should have its own identity with scoped permissions that can be audited and revoked. Not a shared service account. Not inherited permissions from the application that launched it. A distinct identity with its own access boundaries, its own audit log, and its own lifecycle. When an agent is decommissioned, its access goes away. When an agent is compromised, you can isolate it without affecting other agents or human users.
4. Invest in observability that matches the actual system. Logs built for deterministic systems don't fit non-deterministic ones. Traces built for single services don't fit agent meshes. Before you deploy, ask what you'd look at during an incident. If the answer is "I don't know," you aren't ready to deploy. The mental shift here is that observability for AI isn't a downstream tooling choice — it is part of the system's design.
5. Test behaviorally, not just structurally. Static analysis and code review catch some issues. Behavioral testing — adversarial inputs, red-team exercises, edge-case probes — catches different issues. Build a test suite with adversarial prompts specific to your threat model. Run it against every model update. And make the suite look like production traffic, not like a benchmark the model could recognize.
6. Document your uncertainty. The research moves fast. A gap today may close in six months. A defense that worked six months ago may be obsolete today. Keep a running record of what the evidence says and what it doesn't. The organizations that do this well are not the ones with the best tools. They're the ones with the clearest internal view of what's known, what's not, and what they're betting on. Thinking differently means treating your own understanding of the field as a living artifact — not a policy you write once and revisit next year.
What This Means in Practice
The uncomfortable version of this is that AI security is going to be a discipline of managing exposures rather than eliminating them, probably for a long time. That is a different posture than traditional security. It is going to take the industry a while to absorb.
Anyone who tells you they have clean answers to these five questions is either not being honest or not being careful. The honest position is to describe the gap, name the tradeoff, and make the best decision you can with what you have — while the industry figures out how to think differently about what AI security actually requires.
That's the work.
Subscribe to the newsletter for bi-weekly analysis — substack.com/@adversarialminds
Steve Brodson is a cybersecurity architect focused on AI safety and security. He experiments with AI systems, consults with organizations navigating AI risk, and teaches practitioners how to think clearly about threats that don't fit traditional security frameworks. Connect on LinkedIn, X, or at brodson.com.