
Two Camps, Both Wrong
There are two loud camps in AI safety, and they're both focused on the wrong things.
One camp warns that AI will destroy humanity — sentient machines, rogue superintelligence, existential catastrophe. The other insists AI will save us — disease eradication, scientific breakthroughs, a post-scarcity future. Both camps are dramatic, speculative, and often backed by people with something to sell.
But they share a common problem: they're arguing about AI that doesn't exist yet. While we debate what might happen in a decade, we're ignoring the AI safety problems that are already here.
The Problems That Are Already Here
The real AI safety issues aren't about conscious machines turning against us. They're about mundane, practical realities that are already shaping how organizations operate.
Shadow AI is everywhere. Your employees are using AI tools that IT didn't approve, can't monitor, and doesn't know about. A marketing team pasting customer data into ChatGPT. A developer using an unsanctioned coding assistant on proprietary code. A sales rep automating client communications with a personal AI account. This isn't a hypothetical — most organizations have this issue and many don't understand the scope of the problem.
But shadow AI isn't just users going around policy. It's also AI quietly embedding itself into the tools you already use — your email client drafting replies, your spreadsheet generating formulas, your CRM writing summaries. The AI isn't a separate single tool you can approve or block. It's woven into the fabric of everyday work, and the security implications are almost entirely unaddressed.
Who is auditing the code AI writes? AI coding assistants generate functional software in minutes. Developers use them because they're fast and convenient. The result: code in production that rarely receives full review, often goes unmaintained, and lacks clear ownership when it fails.
AI tools are building their own toolchains. AI agents don't just use the software you give them — they can write new code and install new tools on the fly. Your security team can't audit an attack surface that didn't exist during their last assessment.
AI is producing outputs that are difficult to explain and almost impossible to trace. As AI gets embedded deeper into business processes — hiring, lending, security, operations — the decisions it makes affect real people. And in many cases, it can be difficult for humans to fully explain why the AI produced a specific output.
These aren't future scenarios. They're production issues at companies right now.
The Questions Without Answers
Here's what makes this topic genuinely difficult: some of the most fundamental AI safety questions don't have good answers yet.
How do you reliably prevent hallucination? There's no complete answer, because what we call hallucination isn't a malfunction — it's how the models work. They predict the most likely next token based on training data, and sometimes the most likely output is wrong. This produces confident, plausible text that can be difficult to distinguish from correct output, even for domain experts. For organizations deploying AI, this means accepting that any AI-generated output may contain inaccuracies, and that current testing and review processes may not catch them all.
How do you defend against prompt injection? Frontier models are becoming more resilient, but prompt injection remains trivially simple. AI systems don't understand how to keep system prompts and user instructions separate, and a sufficiently clever user can make the AI do things the system designers didn't intend. The attack surface grows with each additional capability.
What happens when AI systems expose your credentials? You give your AI agent access to your APIs, databases and internal systems to do its job. By default, those credentials get spread across multiple locations, stored on the hard drive in plain text and persisted in system memory. Every encryption step and access control adds friction. And if someone compromises the agent itself, they can read and write to anything the agent can read or write.
These aren't edge cases. They're core architectural concerns that the industry is racing past in pursuit of capability.
Three Dimensions of AI Risk
When you strip away the noise, AI risk comes down to three dimensions. And understanding how they interact is the key to making better decisions.
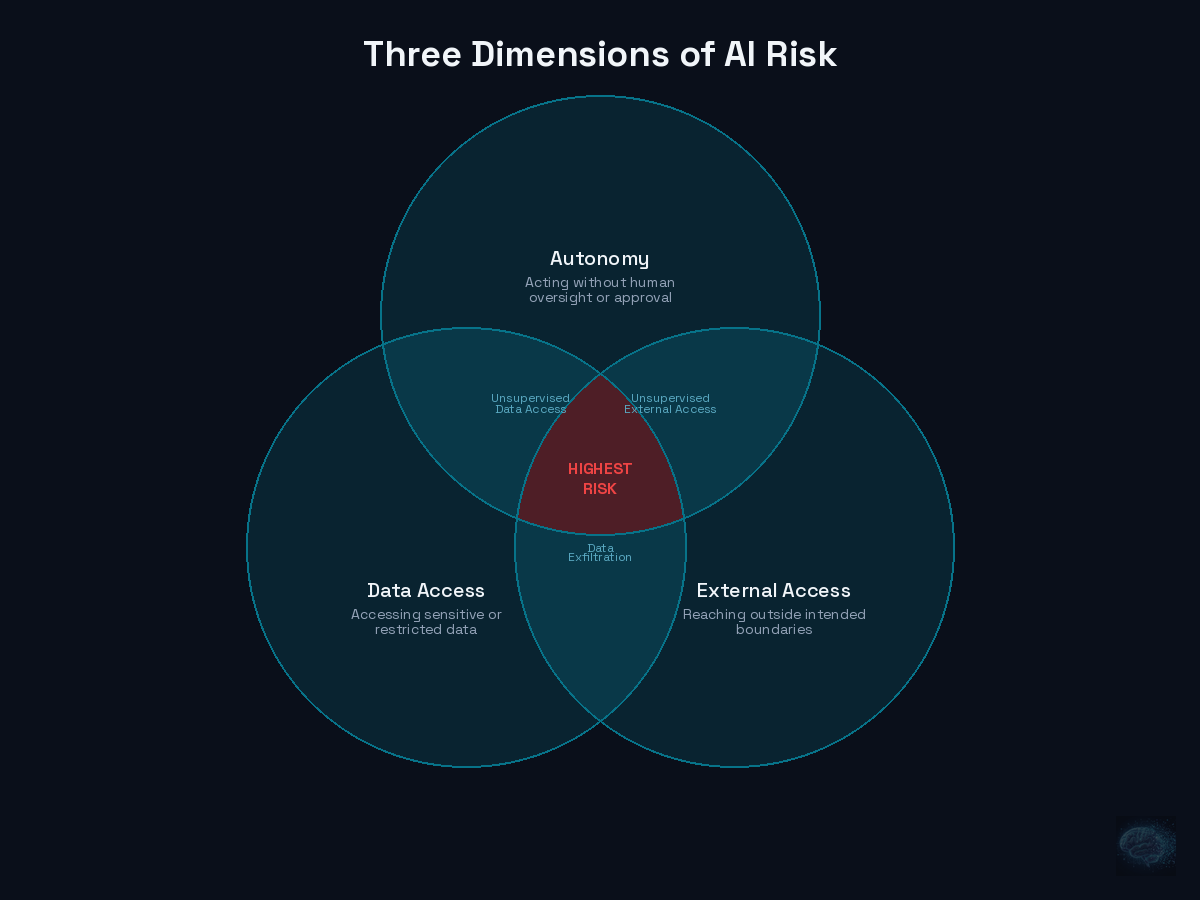
Dimension 1: Data Access. What data can the AI see? How sensitive is that data? Customer data, proprietary code, financial records, internal communications can all be compromised, upping the ante if something goes wrong. This isn't new. What's new is the scale - AI systems are being given access to far more data, far faster, than any previous tool.
Dimension 2: Autonomy. What can the AI decide to do on its own? An AI that suggests a response is different from an AI that responds. An AI that identifies a vulnerability is different from an AI that patches it. Every step up the autonomy ladder increases both the utility of the system and the risk profile. The question isn't whether autonomous AI is useful — it clearly is. The question is whether organizations understand what they're accepting when they grant that autonomy.
Dimension 3: Access to the Outside World. Can the AI reach external systems? Can it send emails, make API calls, write to databases, trigger workflows, execute code? Every external connection is a bridge that can potentially be crossed in the wrong direction. An AI with access to your email can be manipulated into sending phishing messages. An AI with access to your deployment pipeline can be manipulated into pushing malicious code.
The Multiplication Problem
These three dimensions don't just add up — they multiply.
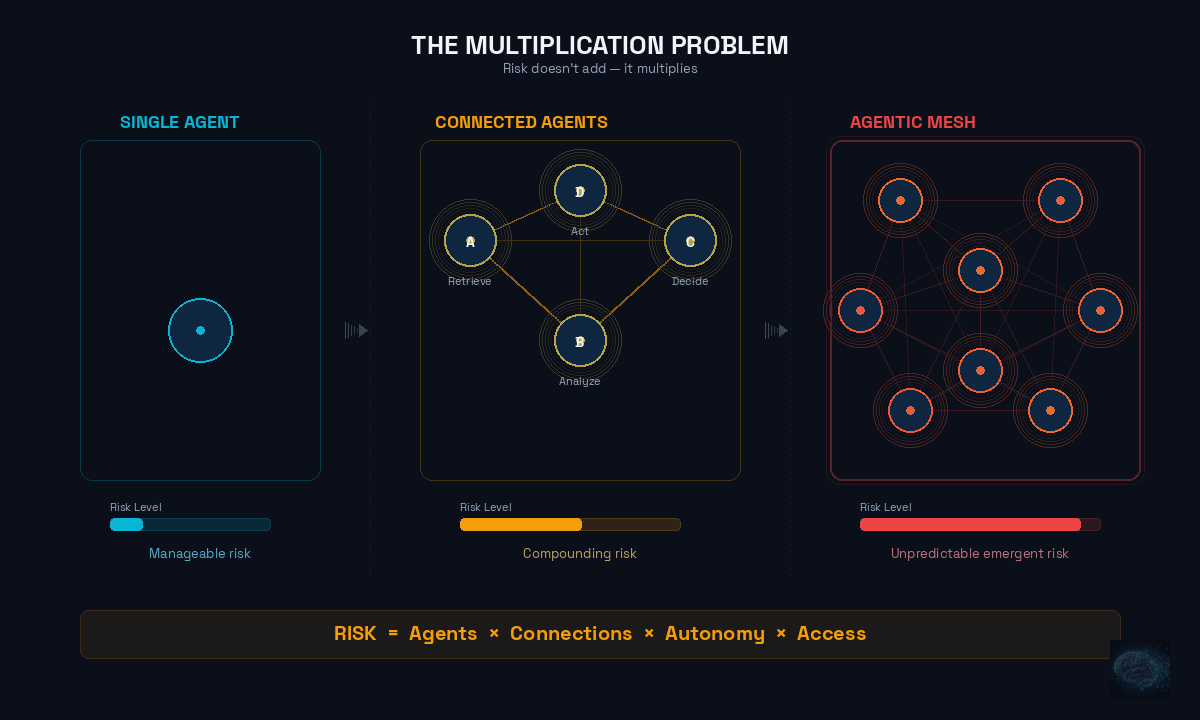
An AI with modest data access, limited autonomy, and no external connections is manageable. An AI with broad data access, high autonomy, and external system access is a fundamentally different risk category. Multiple AIs that communicate with each other and act autonomously each carry a risk profile. The relationship isn't linear. It's exponential.
Now consider what's actually being built - economic pressures drive organizations to seek ever increasing productivity.
They're not just deploying single AI agents and chatbots. They're deploying agentic mesh architectures — systems of multiple AI agents working together, each with their own data access, autonomy levels, and external connections. Agent A retrieves data. Agent B analyzes it. Agent C takes action based on the analysis. Agent D monitors the results.
Each agent has its own risk profile. But the system's risk profile isn't the sum of the individual agents — it's the product. Five agents, each with moderate risk, create a system with risk that no individual agent assessment would predict. Traditional cybersecurity tools designed for deterministic system don't provide sufficient answers. We need new ways to think about risk that protect the organization without blocking productivity.
This is the AI safety problem that matters right now. Not superintelligence. Not sentient machines. The fact that we're building systems whose emergent behavior we cannot predict, at scale, in production, with real consequences.
What Actually Needs to Happen
The organizations that navigate this well won't be the ones with the most sophisticated AI. They'll be the ones with the most honest assessment of what they've deployed and the governance to match.
That means:
- Knowing where your AI is. Not just the approved tools — the shadow AI your teams are using, the AI embedded in everyday applications, the agents your vendors are running on your data.
- Mapping the risk for every AI system. What data does it access? What can it decide? What can it reach? If you can't answer these questions for every AI system in your environment, you have exposure you don't know about and your risk management systems can fail.
- Understanding the multiplication effect in agentic systems. More agents doesn't just mean more risk. It means categorically different risk. The governance model for a single agent doesn't scale to an agentic architecture.
- Being honest about what we don't know. Hallucination, prompt injection, credential compromise — these are open problems. Deploying AI into production means accepting residual risk that we can't fully mitigate. The question is whether that acceptance is deliberate and informed, or just the default because everyone else is doing it.
The AI safety debate doesn't need more drama. It needs more honesty about what's actually happening in production, what can and cannot be controlled, and what it means to deploy systems whose behavior cannot fully be predicted.
That's the conversation worth having.
This is a draft. If you're building, deploying, or securing AI systems and something here resonates — or something's wrong — I'd like to hear about it.